- Published on
Cómo Crear un API Crawler Source en Sitecore Search
- Authors

- Name
- Francisco Caicedo Narvaez
- @_FranciscoCN_es
Overview
Sitecore Search ofrece dos estrategias principales de crawling. El Web Crawler lee las páginas HTML renderizadas, extrayendo contenido mediante selectores CSS y meta tags. Es rápido de configurar, pero fundamentalmente frágil — depende de la estructura del markup, se rompe cuando los templates cambian y solo puede mostrar lo que el navegador ve.
El API Crawler toma un enfoque distinto. Lo apuntas a un endpoint HTTP — en Sitecore XM Cloud, eso significa la Experience Edge GraphQL API — y llama directamente a ese endpoint para obtener datos de contenido estructurado. Los search documents que produce contienen exactamente los fields que tú especificas, con la forma exacta que necesitas. Sin parsing, sin selectores frágiles, sin inclusión accidental del texto de navegación.
El resultado es un search index construido desde la fuente canónica de tu contenido: la base de datos de ítems de Sitecore. Agregar un field a los resultados de búsqueda es un cambio de dos líneas en tu GraphQL query, no una refactorización del markup del frontend.
El pipeline se ve así:
XM Cloud (item DB) → Experience Edge GraphQL → API Crawler → Search Index
En el ejemplo que sigue, construyo un API Crawler source para un directorio de bienes raíces — una implementación real de un proyecto Sitecore XM Cloud.
Arquitectura: El Patrón de Dos Archivos
Para el API Crawler source en este ejemplo sigo convención de dos archivos
| Archivo | Función |
|---|---|
realestate-source.graphql.js | Exporta un string de GraphQL query. Define qué obtener de Experience Edge: templates, paths, fields. Se pega en la interfaz de Sitecore Search como el request body del crawler. |
realestate-source-extractor.js | Exporta una función extract(request, response). Define cómo transformar el response crudo en un array de search documents. También se pega en la interfaz de Sitecore Search. |
Mantener ambos archivos bajo control de versiones junto al código del frontend significa que la estructura del search index siempre es revisable en pull requests y se puede revertir con un
git revert.
Paso 1 — Escribir la GraphQL Query
La GraphQL query se ejecuta contra tu endpoint de Sitecore Experience Edge y devuelve los datos crudos del ítem que el extractor transformará. Comienza por identificar dos piezas clave de información en Sitecore: el template ID del tipo de contenido que quieres indexar, y el item path ID que limita la búsqueda a la rama correcta de tu árbol de contenido.
Cómo encontrar IDs en Sitecore
Abre el Content Editor y navega hasta la definición de tu template o ítem de contenido. El ID del ítem aparece en la barra de estado inferior, por ejemplo:
{37DF6819-BAE5-41C3-8E3F-C176B5176328}. Cópialo incluyendo las llaves.
La query para el source de bienes raíces usa un filtro AND que combina ambas condiciones: solo ítems que coincidan con el template de bienes raíces y que estén bajo el path de contenido de bienes raíces.
# realestate-source.graphql.js
# GraphQL query para obtener páginas de bienes raíces desde Sitecore
# Se usa directamente en la configuración del API Crawler source de Sitecore Search
query ($after: String) {
search(
first: 1000
after: $after
where: {
AND: [
{ name: "_templates", value: "{37DF6819-BAE5-41C3-8E3F-C176B5176328}", operator: CONTAINS }
{ name: "_path", value: "{9C9B87E8-5702-4CCB-BF55-77763D7632EF}", operator: CONTAINS }
]
}
) {
pageInfo {
hasNext
endCursor
}
results {
id
name
url {
path
}
fullAddress: field(name: "PageAddress") {
value
}
image: field(name: "PageImage") {
jsonValue
}
tags: field(name: "PageTags") {
jsonValue
}
}
}
}
Decisiones clave de la query explicadas:
first: 1000— Obtiene hasta 1000 ítems por crawl. La variable cursor$afterypageInfo.hasNextya están incluidos para que la paginación pueda agregarse después sin reestructurar la query. Consulta paginar resultados de Experience Edge para ver el patrón completo de paginación._templatesconCONTAINS— El operadorCONTAINShace match con ítems que heredan del template, no solo con instancias directas. Los ítems construidos sobre templates hijo se incluyen automáticamente.Field aliases —
fullAddress: field(name: "PageAddress")renombra el field crudo de Sitecore a un alias semánticamente significativo en el response. Tu extractor leeitem.fullAddress.valueen lugar de parsear un field llamadoPageAddress.jsonValuevsvalue— Los fields de texto simple usanvalue(devuelve un string). Los fields complejos como imágenes y multilists usanjsonValue(devuelve un objeto estructurado consrc,alt, referencias a ítems, etc.).
Paso 2 — Formatear el Request Body
El API Crawler de Sitecore Search espera que el request esté configurado como un raw HTTP POST body. Las APIs GraphQL se comunican vía HTTP POST con un JSON body que contiene un string query y un objeto variables opcional. La query del Paso 1 debe serializarse a este formato antes de pegarla en el CEC de Sitecore Search.
Serialización
Serializa la query: toma el string de la query, reemplaza todos los saltos de línea con
\n, escapa las comillas dobles dentro de los valores de nombres de fields, y luego envuelve el resultado en{"query": "...", "variables": {"after": null}}.
El resultado se ve así:
{
"query": "query ($after: String) {\n search(\n first: 1000\n after: $after\n where: {\n AND: [\n {\n name: \"_templates\"\n value: \"{37DF6819-BAE5-41C3-8E3F-C176B5176328}\"\n operator: CONTAINS\n }\n ...\n ]\n }\n ) { ... }\n }",
"variables": { "after": null }
}
Paso 3 — Escribir el Document Extractor
El extractor es una función JavaScript plana que Sitecore Search evalúa durante cada ciclo de crawl. Recibe el raw HTTP response de tu endpoint GraphQL y debe devolver un array de objetos document — un objeto por cada search document a indexar.
La firma de la función es fija: function extract(request, response). Sitecore Search la llama con el objeto request saliente del crawler y el response de la API. Los datos reales del ítem están en response.body.data.search.results, coincidiendo con la estructura del GraphQL response que definiste en el Paso 1.
Para la referencia completa de lo que está disponible dentro del extractor, consulta la referencia del JavaScript document extractor.
// realestate-source-extractor.js
// Sitecore Search llama a esta función una vez por ciclo de crawl.
// Devuelve un array — un elemento por search document indexado.
function extract(request, response) {
const data = response.body?.data?.search?.results
const realestate = []
if (data && Array.isArray(data)) {
data.forEach(function (item) {
if (!item) return
realestate.push({
id: item?.id,
type: 'realestate',
page_type: 'realestate',
name: item?.name || '',
realestate_name: item?.displayName || item?.name || '',
realestate_address: item?.fullAddress?.value || '',
realestate_url: item?.url?.path || '',
realestate_image_url: item?.image?.jsonValue?.value?.src || '',
realestate_image_alt_text: item?.image?.jsonValue?.value?.alt || '',
realestate_tags: (item?.tags?.jsonValue || [])
.map((tag) => tag?.displayName)
.filter(Boolean),
})
})
}
return realestate
}
Referencia de field mapping
Cada propiedad que se agrega al array realestate se convierte en un field del documento indexado:
| Index Field | Fuente GraphQL | Notas |
|---|---|---|
id | item.id | Requerido — Sitecore Search lo usa como clave del documento. |
type | hardcoded | Literal "realestate". Se usa para filtrado por tipo en search queries y widgets de resultados. |
realestate_name | item.displayName o item.name | Intenta primero displayName (la etiqueta amigable del CMS) antes de usar el nombre del ítem del sistema como fallback. |
realestate_address | item.fullAddress.value | Mapea al field PageAddress mediante el alias definido en la GraphQL query. |
realestate_url | item.url.path | El URL path para enlazar a la página de detalle del bien raíz desde los resultados de búsqueda. |
realestate_image_url | item.image.jsonValue.value.src | Los fields de imagen devuelven un objeto JSON; .src es el URL, .alt es el texto alternativo. |
realestate_tags | item.tags.jsonValue | Los fields multilist devuelven referencias a ítems; .map(tag => tag?.displayName).filter(Boolean) extrae el label de cada tag. |
Restricciones del extractor
El extractor se ejecuta dentro de un entorno JavaScript sandboxed en Sitecore Search. No puedes usar
import,require,async/awaitni módulos externos — solo vanilla ES5/ES6. La función debe llamarseextracty debe devolver un array. Mantenla completamente autocontenida.
Paso 4 — Configurar el API Crawler en Sitecore Search
Con ambos archivos listos, crea el crawler source dentro del Customer Engagement Console (CEC) de Sitecore Search. Aquí es donde se despliegan la query y el extractor — y donde los autores de contenido gestionan los schedules de crawl y disparan re-indexaciones manuales.
Guía para autores de contenido — Crear el API Crawler Source
Inicia sesión en el CEC de Sitecore Search y selecciona tu domain.
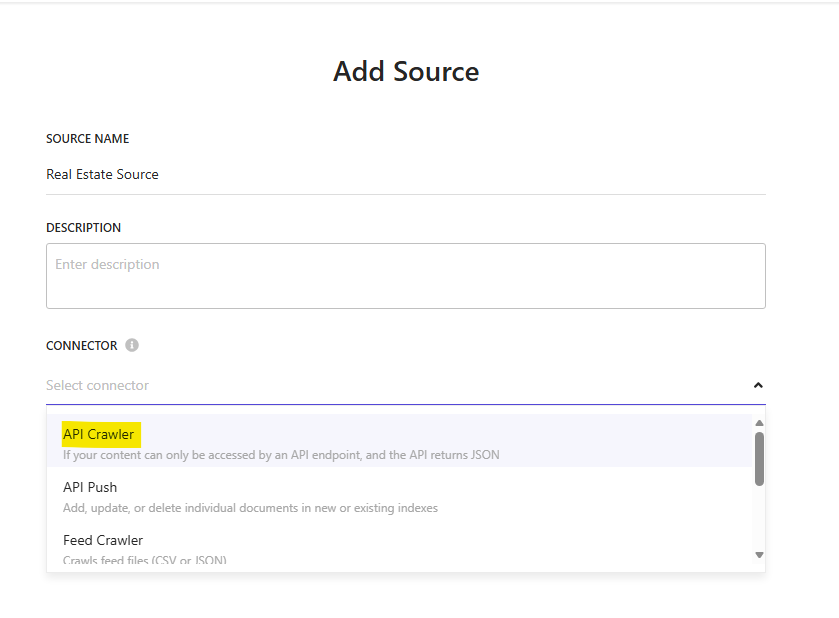
En la navegación izquierda, ve a Integrations → Sources y haz clic en Add source.
Elige API Crawler como tipo de source y dale un nombre descriptivo, por ejemplo, Real Estate Source.
En el campo Endpoint, pega tu URL de Experience Edge GraphQL:
https://edge.sitecorecloud.io/api/graphql/v1Establece el método HTTP en POST y agrega el header requerido:
sc_apikey→ tu API key de Experience Edge.En el campo Request Body, pega el contenido completo de
realestate-source.graphql.post.txt— el JSON POST body formateado del Paso 2.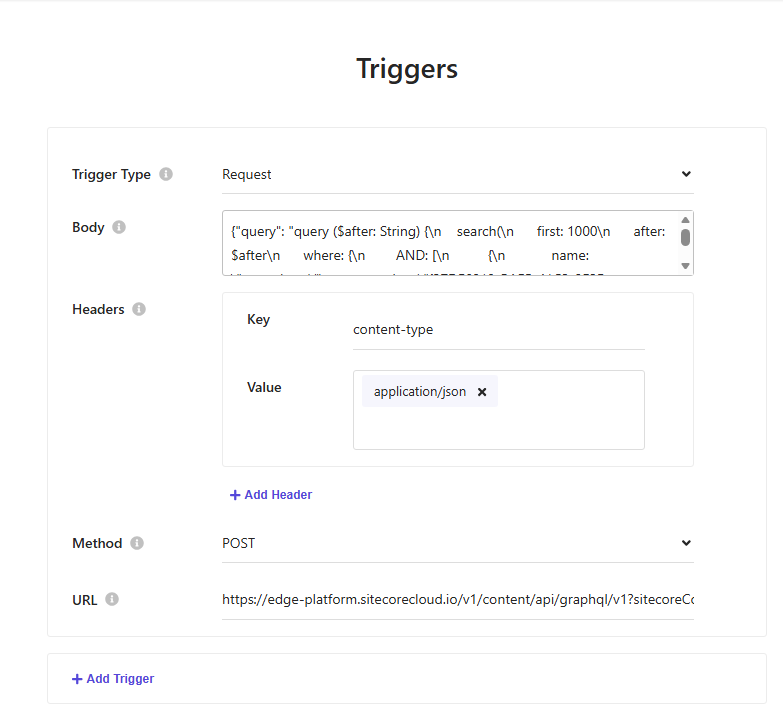
Desplázate hasta la sección Document Extractor. Pega el contenido completo de
realestate-source-extractor.jsen el editor. Consulta Configuring document extractors para el recorrido completo por la interfaz.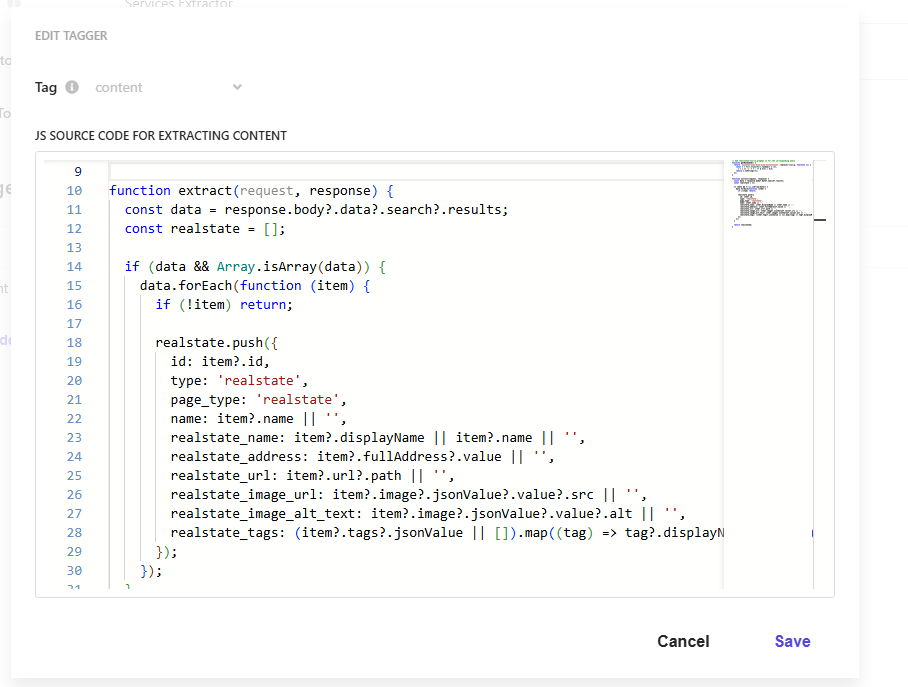
En Schedule, define la frecuencia del crawl. Para contenido que cambia a diario, un crawl nocturno en horas de bajo tráfico funciona bien. Para datos más volátiles, considera ejecutarlo cada pocas horas.
Haz clic en Save y luego en Start crawl para disparar la primera indexación manual.
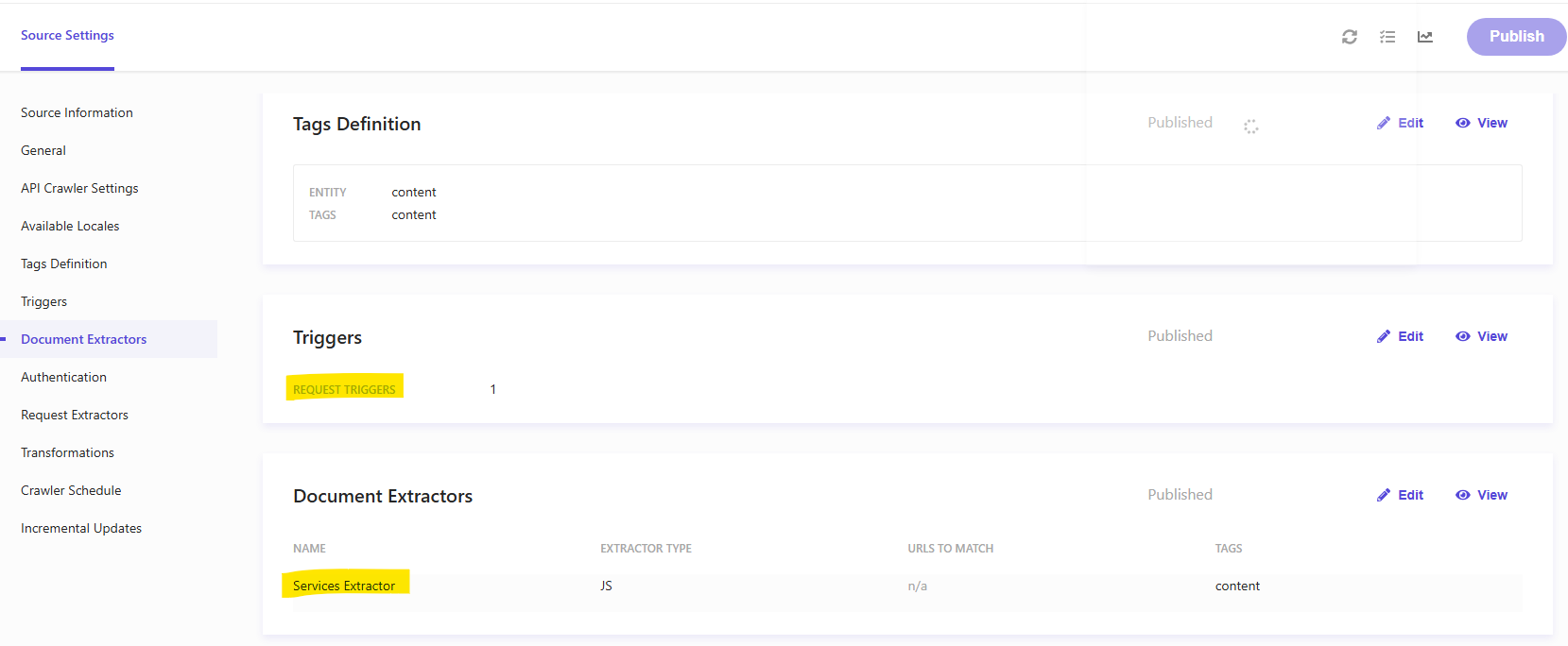
Configuración de attributes
Después de que termine el primer crawl, navega a Integrations → Attributes en el CEC. Sitecore Search habrá descubierto los fields devueltos por tu extractor. Para cada field, configura el tipo de attribute:
- Fields de texto usados para búsqueda full-text (
realestate_name,realestate_address) → Text, indexado para búsqueda - Fields usados como filtros de facets (
realestate_tags,type) → Text, faceting habilitado - Fields de URL e imagen (
realestate_url,realestate_image_url) → Text, no indexado para búsqueda
Consulta Add an attribute para la referencia completa de configuración de attributes.
Paso 5 — Probar y Validar el Index
Una vez que termine el primer crawl, verifica que los documentos se indexaron correctamente antes de conectarlos a un widget del frontend.
Revisar el crawl log
En el CEC, navega a tu source y abre la pestaña Crawl History. Cada ejecución muestra un estado, un conteo de documentos y un error log.
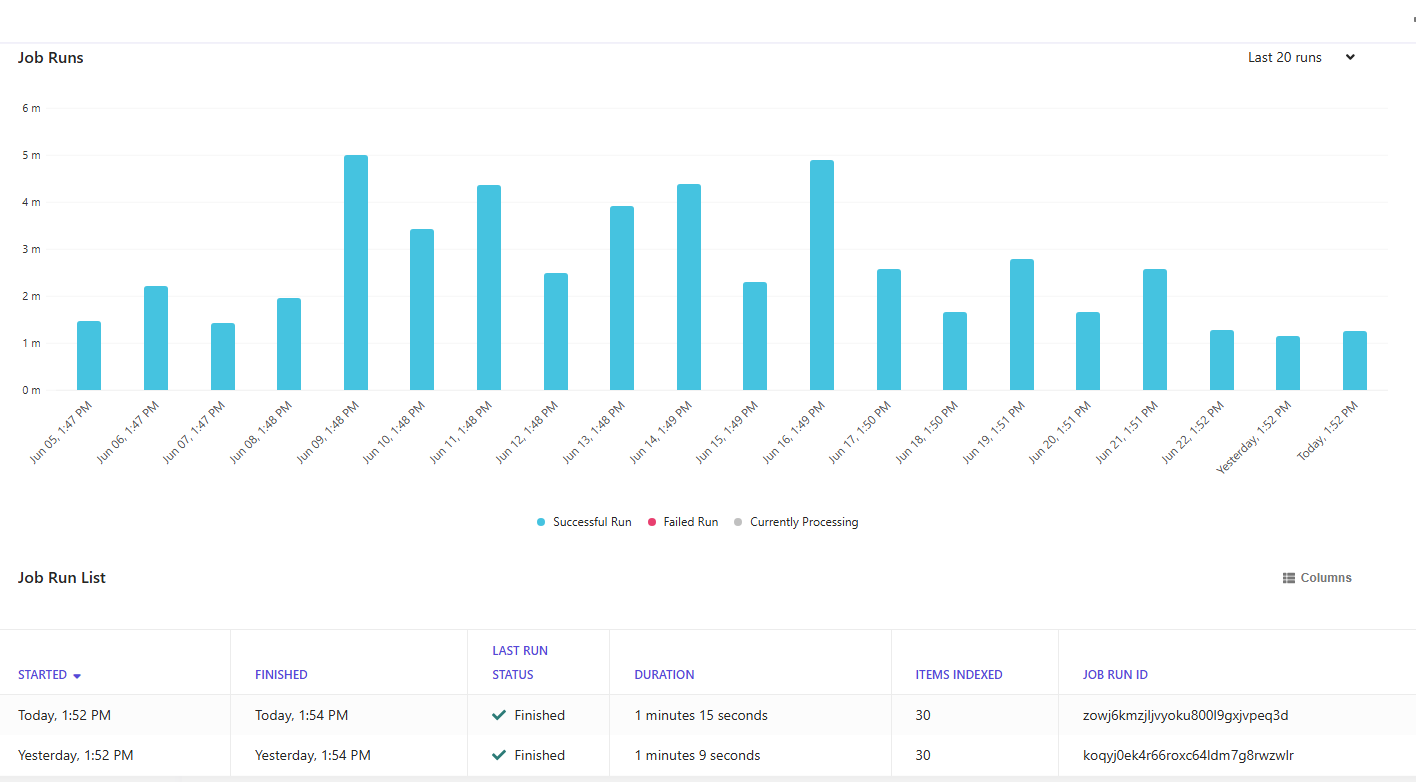
Una ejecución exitosa mostrará un conteo que coincide con el número de ítems devueltos por tu GraphQL query. Si el conteo es cero, verifica:
- La URL del endpoint y el valor del header
sc_apikey - Que los IDs de template y path en la query coincidan con tu entorno destino
- Que la función
extractdel extractor devuelva un array no vacío para input válido
Sobre actualizaciones incrementales
El API Crawler re-indexa todos los documentos en cada ejecución de crawl — no soporta actualizaciones delta de forma nativa. Para sources donde el contenido cambia con poca frecuencia (como un directorio de bienes raíces), una re-indexación completa nocturna es aceptable. Para datos de alta rotación, investiga la push ingestion API de Sitecore Search como complemento para actualizaciones en tiempo casi real entre crawls programados.
Beneficios
El patrón de dos archivos del API Crawler parece una inversión inicial pequeña, pero los retornos se acumulan:
Indexación precisa y predecible — Tú defines cada field del index. Sin inclusión accidental de texto de navegación, footers o metadata del CMS.
Resistente a cambios — Las refactorizaciones de templates del frontend no rompen la búsqueda. La query lee directamente desde la base de datos de ítems; la búsqueda está desacoplada de cómo se renderiza el contenido.
Control de versiones — Ambos archivos viven en tu repositorio Git. La estructura del search index se revisa en pull requests, se etiqueta en releases y es segura para hacer rollback.
Lista para múltiples sitios — Un solo source puede agregar contenido de múltiples sitios XM Cloud usando lógica OR en los paths, con tagging por sitio para experiencias de búsqueda limitadas.
Tipos de fields enriquecidos — Atributos GEO, arrays multilist, traversal de ítems enlazados — funcionalidades imposibles con un HTML crawler se vuelven directas cuando controlas la forma de los datos en la capa GraphQL.
Escala con confianza — El cursor de paginación (
$after) ya está integrado. Cuando tu biblioteca de contenido supere los 1000 ítems, agregar crawling paginado es un cambio puntual, no una reescritura.
Conclusión
El API Crawler de Sitecore Search es la herramienta correcta cuando necesitas un search index que refleje con precisión contenido estructurado, no un scrape de mejor esfuerzo del HTML renderizado. Al mantener la GraphQL query y el extractor como archivos fuente de primera clase en tu repositorio, aplicas todos los beneficios del control de versiones, la revisión de código y el tooling de desarrollo a lo que tradicionalmente ha sido una operación de "pegar en la interfaz de admin y esperar lo mejor".
Lecturas adicionales
- Configure an API Crawler — Recorrido paso a paso por el CEC para crear un API Crawler source
- Walkthrough: Configuring an API Crawler — Tutorial guiado con capturas de pantalla
- Create a JavaScript Document Extractor — Referencia completa de la función API del extractor
- Configuring Document Extractors — Cómo configurar extractors en el CEC
- Attributes Overview — Entender y configurar attributes del index
- The Experience Edge Schema — Referencia del schema GraphQL para Experience Edge